

Safe and Secure Field Updates of Embedded Linux Systems
In this blog post I would like to address the challenges of performing unattended and verified updates of embedded Linux systems in the field using open source software and workflows. While updating is not a end in itself, a second part of my considerations goes even further and also works out the necessities and possible workflows for keeping the software stack of a project up to date and thus either preventing security issues or at least enabling a short reaction time in case of severe CVE'S discovered.
This blog post is mainly based on a talk and paper I prepared for the Embeeded World Conference 2019 in Nürnberg.
Introduction
The ability to deploy software updates is an indispensable requirement for a modern state-of-the-art embedded platform. Regardless of whether due to critical CVEs, functional bugs, adaption to new requirements or for adding new features to stay competitive on the market, the software of these systems needs to be constantly adjusted.
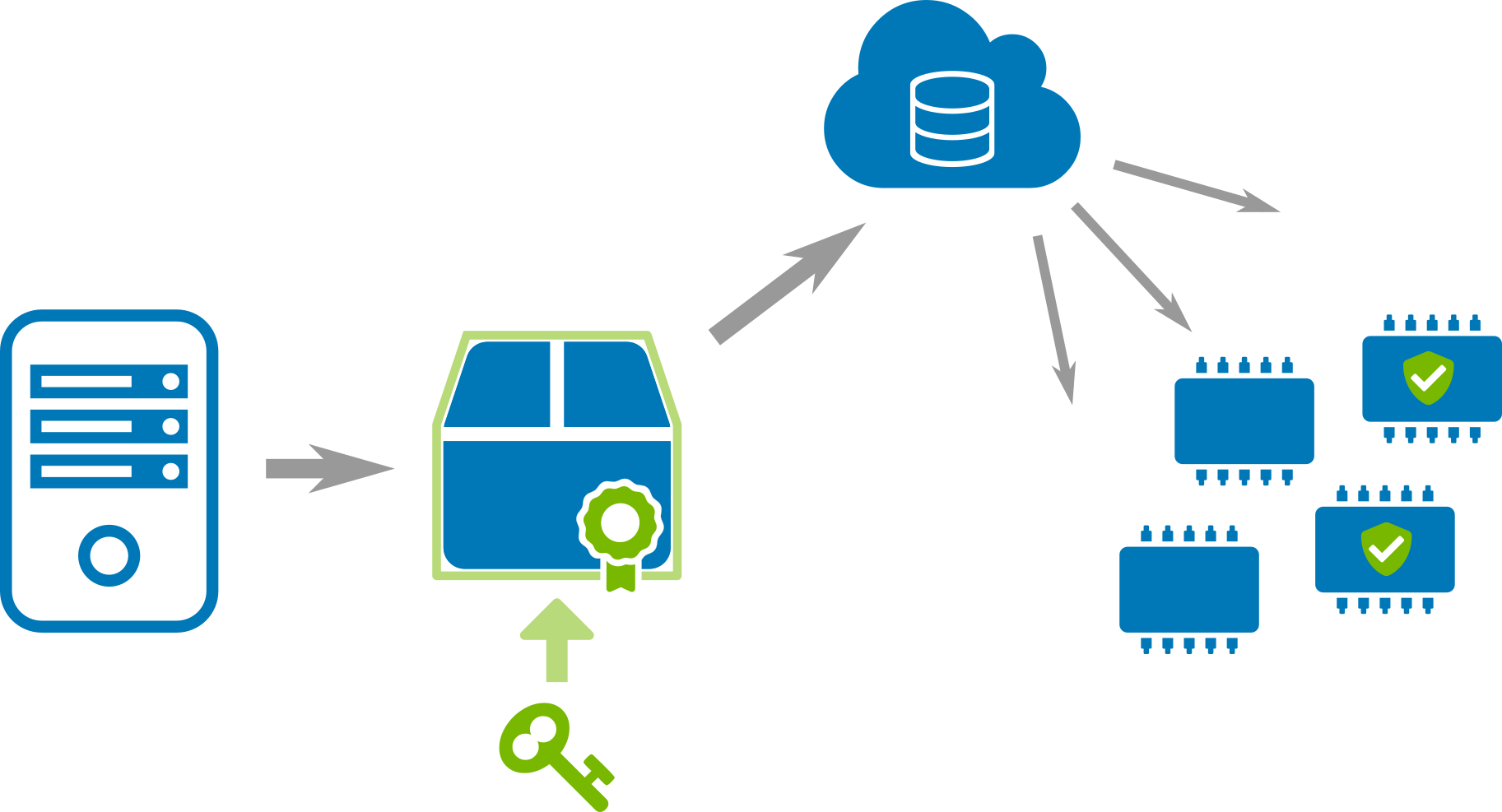
However, having an update service running on a device also adds both a new attack vector as well as a risk for bricking the device during or after an update. Thus implementing it needs certain care to make it robust and secure.
Nowadays the availability of several open source update tools has finally overcome the times of immature and semi-secure hand-coded scripts and allows to focus also on more advanced topics. But, it is also still essential to know and understand the basic requirements and possible pitfalls very well to make the right decisions regarding the overall platform and workflow design.
This paper first addresses the principles of redundant image-based update concepts followed by fundamentals of fail-safe updating and runtime handling. Then it shows how to deal with security-related questions as authentication and strategies and workflows for preventing and quickly fixing CVEs in the field. Finally it provides a short overview over RAUC as one possible available open source implementation of an update framework.
Image-Based Updating
Updating the software of an embedded system differs significantly from updating a server or a PC. Embedded devices often allow none or only fairly limited user interaction, making them unsuitable for package-based updates as one would use on a PC or a server. Package-based updates can lead to conflicts or inconsistent states that require human intervention. But the most relevant drawback of conventional package-based updates is that these can lead to combinations of libraries and applications on the target that were never tested before and thus are likely to fail.
The decision about which alternative method to choose for performing updates also depends on the considerations which kinds of failures one expects and needs to protect against and which parts one expects to need to be updated. Container-based updates for example would allow to flexibly exchange the upper layers of a system, but prevent one from being able to fix bugs in the host system or the kernel. Additionally, this assumes that the underlying file system never becomes corrupted, which also is a critical risk for file-tree based update mechanisms.
Thus, the only way allowing to fully replace the old system with a well-defined new software state while being almost immune against file system corruption etc. is to use full image-based updates. This means that one always installs the entire root file system and kernel of the new Linux system. This can either be done by writing a pre-generated file system image to the device or by formatting the device and unpacking the content of an archive to a newly initialized filesystem.
In the following descriptions we will consider image-based updates only.
Redundancy and Atomicity
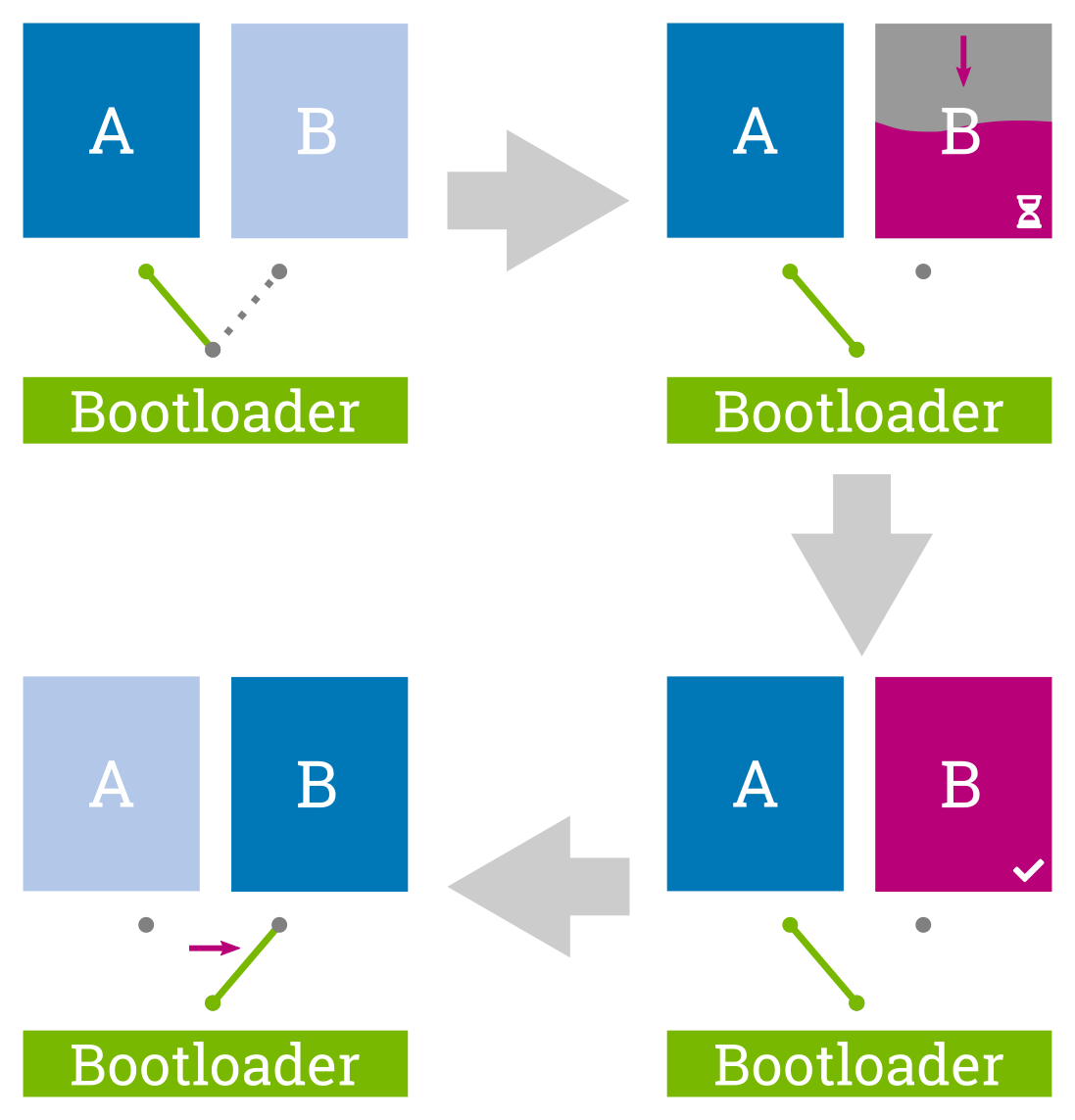
Flow for atomic update with redundant partitions (A/B update)
For being fail-safe the update process must be atomic. This means that an update is either considered fully installed or not, independent of possible interruptions. There must not be a critical phase in which e.g. a sudden power loss will lead to a bricked device. This means, that if anything goes wrong during the processing and writing of the update, the currently running system must remain unaffected.
The implication on such a system is that it must be designed to be redundant; either by having one dedicated update/recovery partition and one system partition (A/recovery scenario) or by using a fully-redundant set of system partitions (A/B scenario).
The A/B case nowadays is the default on systems that are not storage-limited as it adds multiple benefits; a) an update can be performed entirely in the background while the main application proceeds; and b) in case of a failure in the currently running system one has the option to fall back to an older system state on the other partition to guarantee service availability. In addition to these 'standard' cases also more advanced configurations such as A/B/recovery or combining the redundant system partition with a separate but linked redundant application partition are possible.
Updating redundant partitions atomically requires the system to have a single dedicated switching point that allows moving from the updating system to the updated one at the very end of the update process.
For image-based updates, this switching is normally done in the bootloader and must itself be atomic. This is why the bootloader plays an important role in a redundant update concept and must be chosen and configured carefully.
Although the bootloader is normally the only component of such a system that is not fully redundant, one may also come in situation where a bootloader update cannot be avoided. Assuming the bootloader was well-tested before, the most critical point for a bootloader update is the step of actually writing the bootloader which is often vulnerable to power loss.
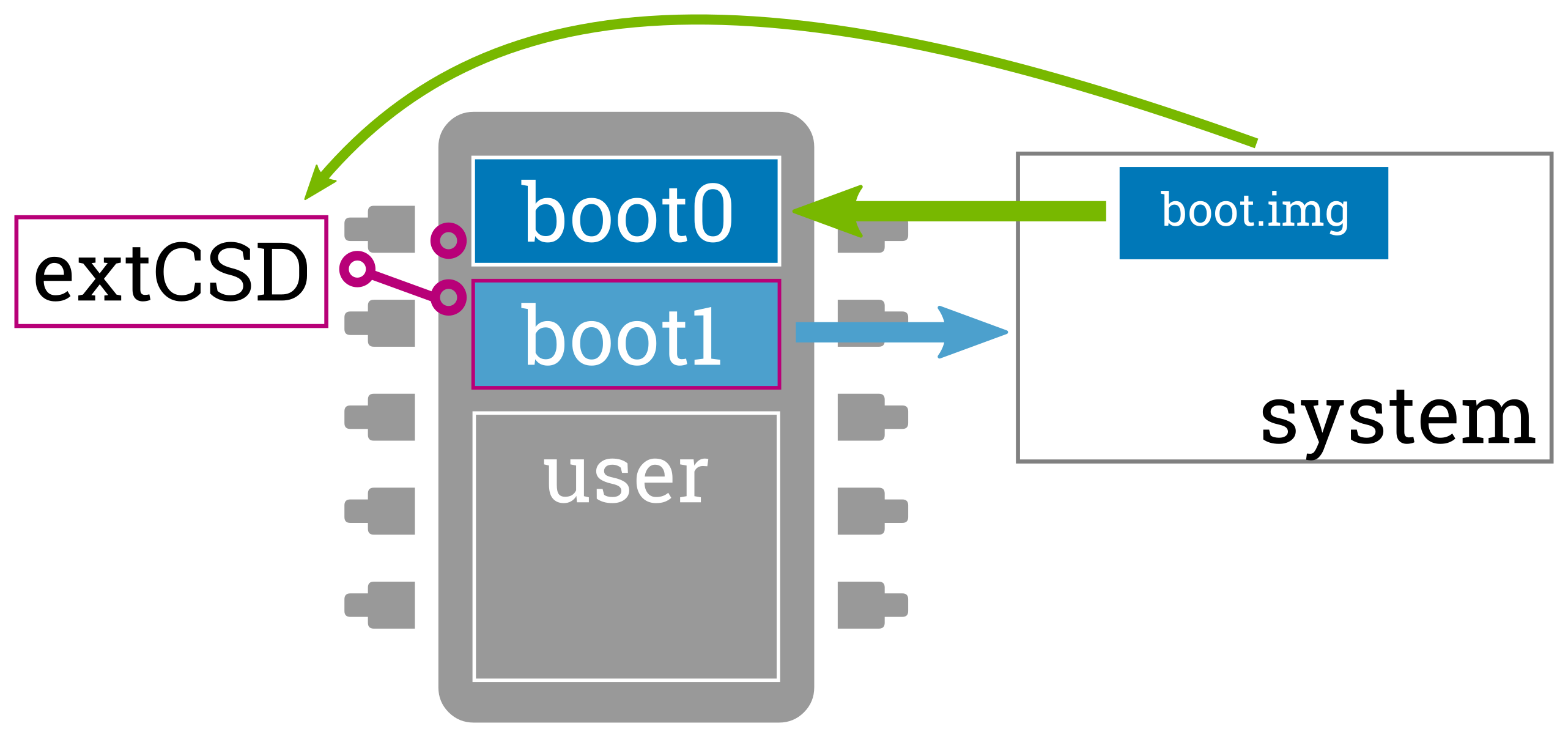
eMMC-enabled atomic bootloader updates
An update design always also depends on the abilities and limitations set by the used hardware. The bootloader update scenario is a fitting example how a good hardware design can improve or simplify the update design. When using an eMMC as storage it is possible to also perform bootloader updates atomically: An eMMC provides two dedicated built-in boot partitions boot0 and boot1 that are selected (by supporting ROM loaders) depending on a switchable flag in the eMMC's extCSD register. Thus when having boot0 partition active, one can safely write the updated bootloader to the boot1 partition and switch it to be the active boot partition only after successful writing. If writing fails or is interrupted, the ROM loader will continue to boot from the valid boot0 partition.
Using eMMC in general adds several benefits to embedded systems compared to raw NAND. Its full abstraction as a simple block device hides all internal quirks for the flash and allows using well-proven standard Linux file systems such as ext4 without having to care about wear leveling, etc.
Detecting and Handling Runtime Failures
As important as making the update process itself robust is to also prepare the system for being fail-safe against runtime issues. Regardless of how intensively a new software state was tested, it may nevertheless trigger errors in the field that were not covered by testing, e.g. because of specific environmental conditions.
The most frequent class of potential failures is that the device hangs during the boot process or that a software component in the running system exits or hangs. These hangs can be detected and handled by using hardware and software watchdogs. A watchdog is like a simple timer that must periodically be triggered. If the system or a systems component hangs and the watchdog is not triggered anymore for a defined period of time, the watchdog will force the entire system to be reset and booted again.
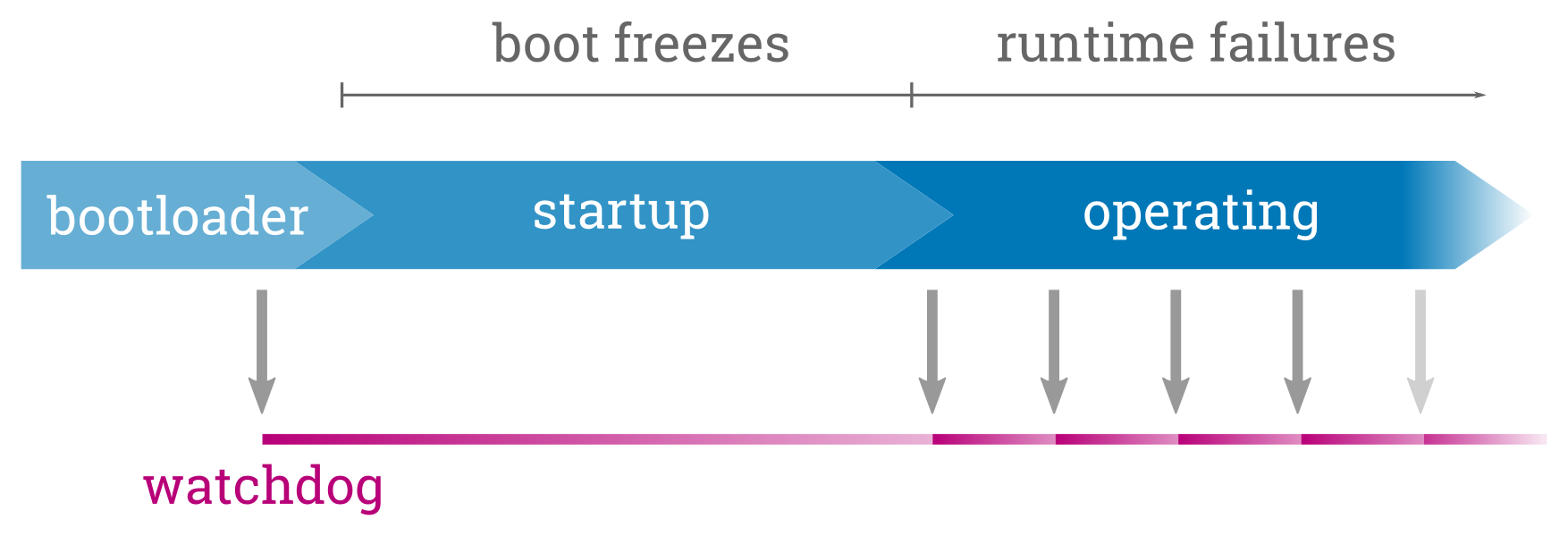
In a redundancy boot setup this reset also allows to perform a fallback to the old system in case of too many failures in the new one. Bootloaders normally can maintain some kind of an attempts counter for this that will be decremented on each boot and reset only when the system was booted successfully. If the system failed booting several times, this counter will become zero and the bootloader switches to boot the fallback system. While most bootloaders require scripting for this, the barebox bootloader provides a dedicated redundancy boot framework called bootchooser backed by a storage backend that allows to atomically change one or several variables. A similar mechanism is also provided by systemd-boot and U-Boot provides a simple boot counter.
For detecting and handling process hangs and failures in the running system, the systemd init system, which is nowadays standard on most Linux distributions, provides a huge and powerful set of tools to decide on when and how to restart services or applications. It also provides a watchdog multiplexer that allows to have unlimited software watchdogs backed by only a single hardware watchdog allowing to monitor all safety-critical applications.
Authentication
Transport authentication vs. artifact authentication
Having the ability to update the entire system to a desired software state also enforces to prevent unauthorized persons from accidentally or intentionally deploying wrong or malicious software to the device. While the first case is mainly a safety issue and can be prevented by simple mechanisms as comparing an identifier that must match between the target and the update preventing unauthorized access is quite more complex.
Authentication always requires well-proven security implementation and knowledge of the possible scenarios one needs to protect against to also use it properly. What is true for most parts of a system is the most important for security: one should not implement cryptography on one's own as this is highly prone to introducing mistakes. Instead one should use well-proven standard libraries such as OpenSSL.
Despite more and more systems becoming connected over networks, the classical USB stick update case is still a very common scenario. Allowing to provide verification for both network and USB case one cannot rely on encryption protocols like TLS. A proper solution to this can be to use X.509 cryptography (which is also the base for TLS) in the form of CMS (Cryptographic Message Syntax) as signature format and directly sign the update artifact.
With X.509 cryptography one gains the flexibility to cover a wide range of requirements, from a simple self-signed certificate to advanced public key infrastructures (PKI) with multiple signers, certificate revocations lists (CRLs) and much more. Some base considerations targeting this topic are differentiation between development and release key, the usage of per-device keys, etc.
Software Maintenance Cycle
When thinking about security, one has to have in mind that one of the most important aspects to keep the system secure is the presence of the update solution itself. It allows to deploy fixed software and thus lowers the risk of the device being compromised. But, this is only true if one is also able to deliver updates quickly if required.
By using Linux, most of the software on the platform will be open source. And thus, most of the fixes for CVEs and other bugs will not be provided by the platform developer but are contributed continuously to the different upstream projects by the open source community.
Having a maintenance strategy that follows these upstream projects in regular intervals and encourages submitting modifications made to software components back to the upstream projects as early as possible will keep the custom stack of modifications small and assures these roundtrips can be performed with manageable effort each. This strategy both ensures collecting existing bugfixes as well as enables to apply future urgent bug fixes within a minimum amount of time and effort. Embedded Linux build systems such as Yocto, PTXdist or Buildroot already do most of this version bumping work so that following their releases will already do 90% of the job. Together with an appropriate revision control system, such as Git, these build systems also enable to fully persist and rebuild any software state. Reproducibility is a key requirement for debugging issues that arose in the field for a specific software version.
If one instead picks a fixed software state in an early project phase and continues developing on this same state several years until finally deploying it into the field this results in the software being already quite obsoleted at that point. Despite most projects provide stable and also long term stable (LTS) updates, one has to bear in mind that these periods are usually much shorter than the sum of development plus product life time. Thus updates will not be available anymore soon after deploying the software. Another important aspect is that most of the bugfixes that are part of an LTS were discovered and fixed from a much more recent software version where they have far better test coverage by people that use it. Thus backporting patches to an older software state does not automatically mean more stability!
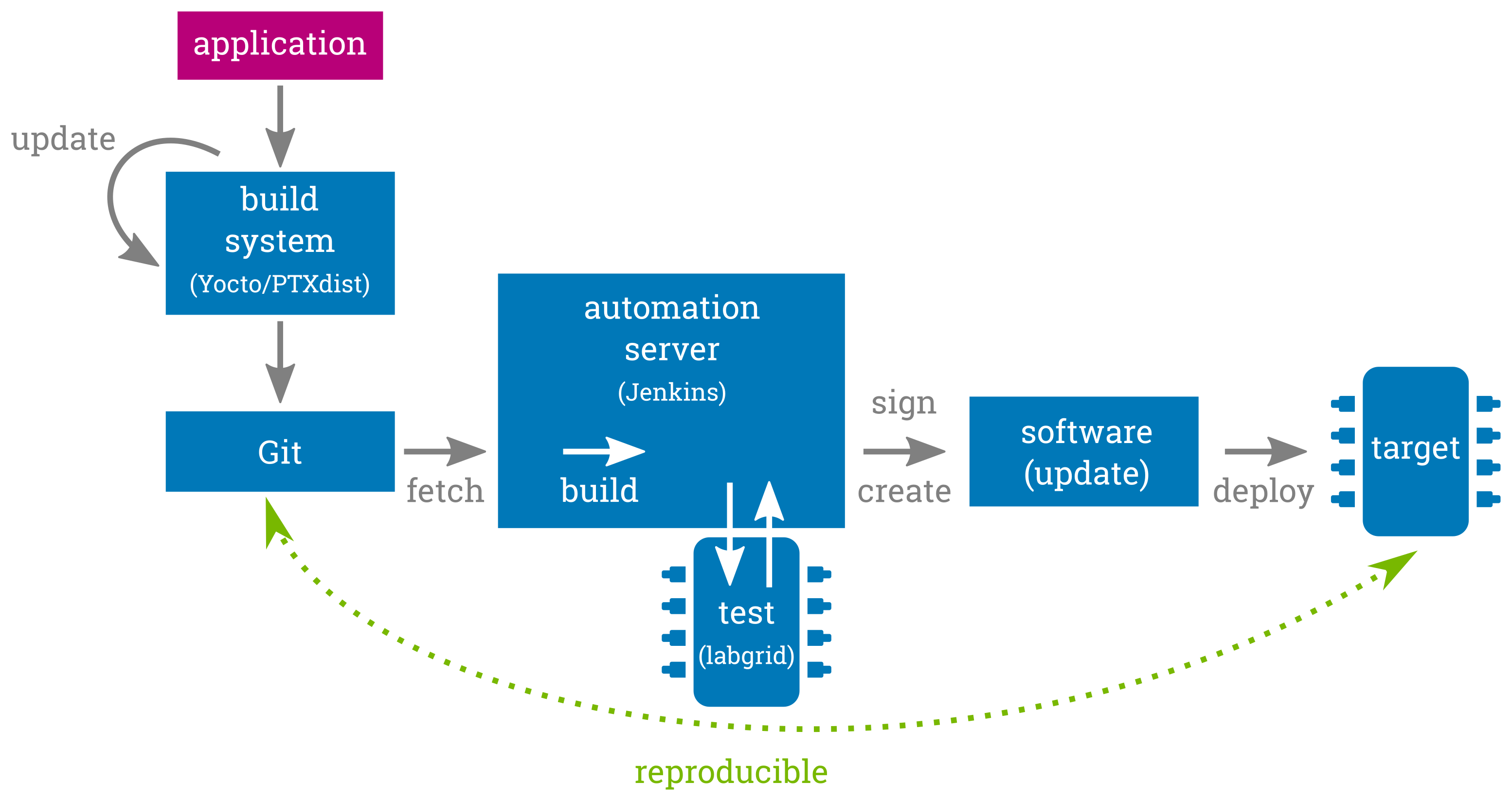
A good advice is to keep the entire software stack up-to-date during the development phase of the project, where minor issues still can be quickly fixed without a larger impact. This ensures having a recent software stack when releasing the embedded Linux platform.
Another important aspect for easing maintenance cycles is to have an automatic CI-like full system test setup driven by automation servers like Jenkins1 and hardware control frameworks such as lava2 or labgrid3. This allows to detect potential issues during platform upgrades quite quickly and also lowers the probability of missing bugs that first appear in the field where it is more expensive to fix them.
Data Handling
An important aspect to also think about when designing a redundant update system is on how and where to store application and configuration data. Many systems use a dedicated data partition separate from the root file system for storing all or parts of this information. This can either be one single partition for both A and B systems or it can itself be redundant with a fixed allocation of each data partition to either belong to the A or B system. However, in both cases one might need to migrate data from one to the other system and application version. For the redundant case it must be defined if it is valid to operate on old data or not, etc. The actual decisions that are required in that context are always highly use case-specific.
Open Source Update Frameworks: RAUC
Over the last years different open source update frameworks came up, each with slightly different focus and capabilities. The most visible ones are mender, swupdate and RAUC. These framework do most of the basic work like bootloader interaction, redundancy handling, signing and verification. But using them still requires proper integration into a (complex) overall system where all the different components must be well configured to properly interact to ensure robust and fail-safe handling as pointed out in the previous sections.
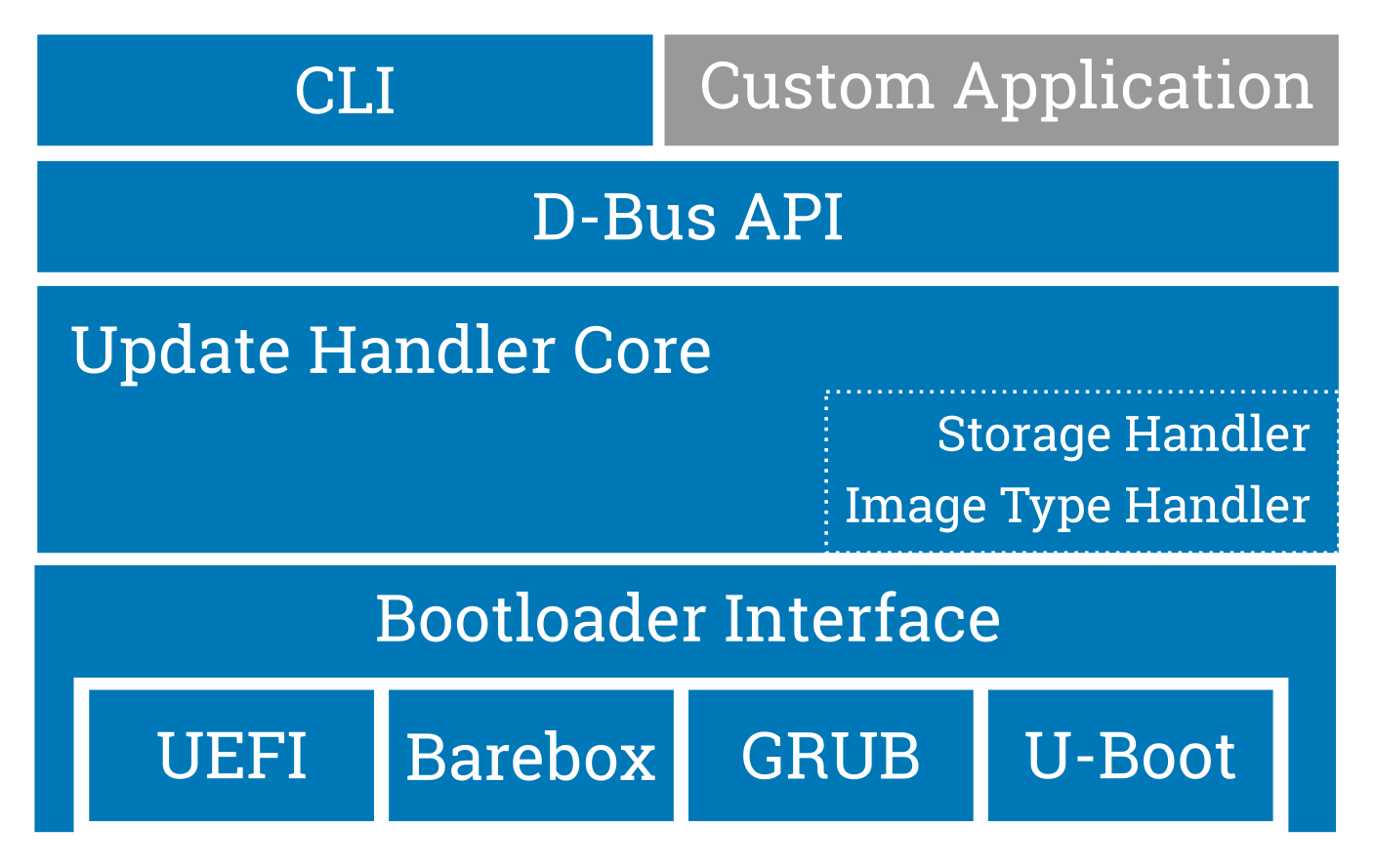
RAUC scheme
RAUC for example is a flexible update framework supporting a variety of platforms, storage types, file systems and bootloaders, including GRUB, barebox, U-Boot and UEFI.
A simple ini-style config file placed on the target system maps the existing partitions to a number of so-called 'slots' that are assigned to different classes based on their purpose and grouped with other slots to form sophisticated redundancy scenarios.
On the host system RAUC allows to create and install compressed and signed so-called 'bundles'. These bundles contain the actual images and other artifacts to install together with a manifest file describing which image is intended for which slot class as defined in the system configuration of the target. It also provides global and per-slot configuration options and extension by hook scripts for fine-tuning and customizing the actual installation behavior to match the individual project's needs.
While RAUC provides a full-featured command-line interface that allows installing bundles and inspecting the system state, RAUC is primarily designed to be integrated in existing applications and thus can be fully controlled using its D-Bus interface. This is a deliberate design decisions as normally the main application running on an embedded systems needs to keep control over triggering or monitoring the update process.
RAUC uses the CMS standard (X.509) for signing and bundle verification with some useful features such as resigning bundles when moving from development to production or support for PKCS#11 (SmartCards).
Although RAUC is an image-based updater it also allows installing images via tar archives to be independent from the actual storage media size. RAUC also supports binary delta-like streaming of updates by making use of the casync data chunking tool.
RAUC is purely written in C using the GLib library which allows to have a small footprint and prevents from reinventing the wheel. For cryptography it uses the OpenSSL library and the curl library for network transport protocol functionality. It is licensed under LGPL2.1.
Conclusion
Open source update frameworks play an important role when designing a redundant update concept for an embedded (Linux) platform. They solve the basic challenges like atomicity, redundancy, verification and bootloader interaction and avoid reinventing the wheel in each project. Considering safe and secure updates necessarily also involves keeping the project's and the target's software stack up-to-date to prevent attacks and enable quick reaction in case of severe issues. Understanding and making use of the communities and work flows of open source software can safe a lot of effort during a device's development and lifetime.
Weiterführende Links

RAUC und labgrid Sponsoring-Pakete ab jetzt im Shop!
RAUC und labgrid sind Open Source Software-Projekte, die beide bei Pengutronix gestartet wurden und in ihren jeweiligen Nischen mittlerweile recht erfolgreich geworden sind. Ab heute ist es möglich Sponsoring-Pakete im Linux Automation GmbH Shop zu erwerben, die die Entwicklung dieser Projekte unterstützen.RAUC v1.15 Released
It’s been over half a year since the RAUC v1.14 release, and in that time a number of minor and major improvements have piled up. The most notable change in v1.15 is the newly added support for explicit image types, making handling of image filename extensions way more flexible. Other highlights include improved support for A/B/C updates and several smaller quality improvements. This release also includes the final preparations for upcoming features such as multiple signer support and built-in polling.
RAUC - 10 Years of Updating 🎂
10 years ago, almost a decade before the Cyber-Resilliance-Act (CRA) enforced updates as a strict requirement for most embedded systems, Pengutronix started RAUC as a versatile platform for embedded Linux Over-The-Air (and Not-So-Over-The-Air) updates.

Netdevconf 0x16
Nach längerer Zeit mit nur Online-Events findet 2022 auch die Netdev 0x16, eine Konferenz rund um die technischen Aspekte von Linux Networking, hybrid statt - online und vor Ort in Lissabon.
CLT-2022: Voll verteilt!
Unter dem Motto "Voll verteilt" finden die Chemnitzer Linux Tage auch 2022 im virtuellen Raum statt. Wie auch im letzten Jahr, könnt ihr uns in der bunten Pixelwelt des Workadventures treffen und auf einen Schnack über Linux, Open Source, oder neue Entwicklungen vorbei kommen.

Wir haben doch etwas zu verbergen: Schlüssel mit OP-TEE verschlüsseln
Moderne Linux Systeme müssen häufig zwecks Authentifizierung bei einer Cloud- basierten Infrastruktur oder einer On-Premise Maschine eigene kryptografische Schlüssel speichern. Statt der Verwendung eines Trusted Platform Modules (TPM), bieten moderne ARM Prozessoren die TrustZone-Technologie an, auf deren Basis ebenfalls Schlüssel oder andere Geheimnisse gespeichert werden können. Dieses Paper zeigt die Nutzung des Open Portable Trusted Execution Environments (OP- TEE) mit der Standardkonformen PKCS#11 Schnittstellen und i.MX6 Prozessoren von NXP als Beispiel.